markdown-pdf
Categories: python python libraries

The markdown-pdf module allows us to create PDF documents, via Python code. It takes a markdown formal file as its source, which is a simple text file that an be easily generated by hand, or created using Python code.
What is PDF
PDF is a standard file format for storing documents containing formatted text, images, and other elements. Unlike many other popular formats, the content of a PDF file will have an identical appearance wherever it is viewed. You can use any PDF reader software on any operating system, and the content will look exactly the same. You can view it on the web, using any browser, or print it on any office printer, or sell it on Amazon as either an ebook or a physical book, the content will always look exactly the same.
This level of versatility and predictability makes PDF a very useful format whenever you want to guarantee the appearance of the document. For example:
- A report, where you might want to avoid data tables potentially getting mangled when someone views it.
- An invoice, where you need to be sure the company branding and billing information are preserved.
- A brochure, where you want the customer to see it exactly as the marketing department intended.
- A book, where it might be very important that certain text and images appear together on the same page.
If you need to control the exact appearance of the document, or if you just want it to look nice when viewed on any system, PDF is a good choice.
Generating PDF
In some cases, you might wish to generate PDF documents automatically, for example, a report or invoice, as mentioned above. There are Python libraries for creating PDF files that offer very precise control of the exact appearance of the document. However, we don't always need to control the position of every element to the nearest pixel. Sometimes we just need to create documents using a method that is reliable, repeatable, and looks good.
In that situation, markdown-pdf can be a great compromise. It takes one or more markdown documents and creates a PDF based on them. This is particularly useful if you are already familiar with markdown, although markdown is pretty easy to learn. Markdown provides a simple, text-based syntax that allows for:
- Paragraph text
- Bold and italic styling
- Headings
- Images
- Bulleted list
- Hyperlinks to external websites or other parts of the document
- Tables
Among other things. We won't look at markdown syntax in detail here.
Since markdown is a text-based format, it is easy to create a document in a normal code editor. Most modern editors support syntax highlighting for markdown.
markdown-pdf will then convert the markdown text format into a fully formatted PDF, using different styles for headings, laying out lists and tables, and adding any images that are requested in the markdown.
You can control the style of the document using standard Cascading Style Sheet (CSS) files, exactly as you would use to style a web page. Again, if you are familiar with CSS, this makes life very easy. But even if you do not already know CSS, it isn't difficult to learn the basics.
Finally, since the source is a simple text file, you can use Python to create content. For example, if you are compiling a report from data in a spreadsheet, it is pretty easy to generate a markdown table with Python code. Then markdown-pdf will convert the table into a nice format for the final PDF.
Creating a PDF from a simple markdown file
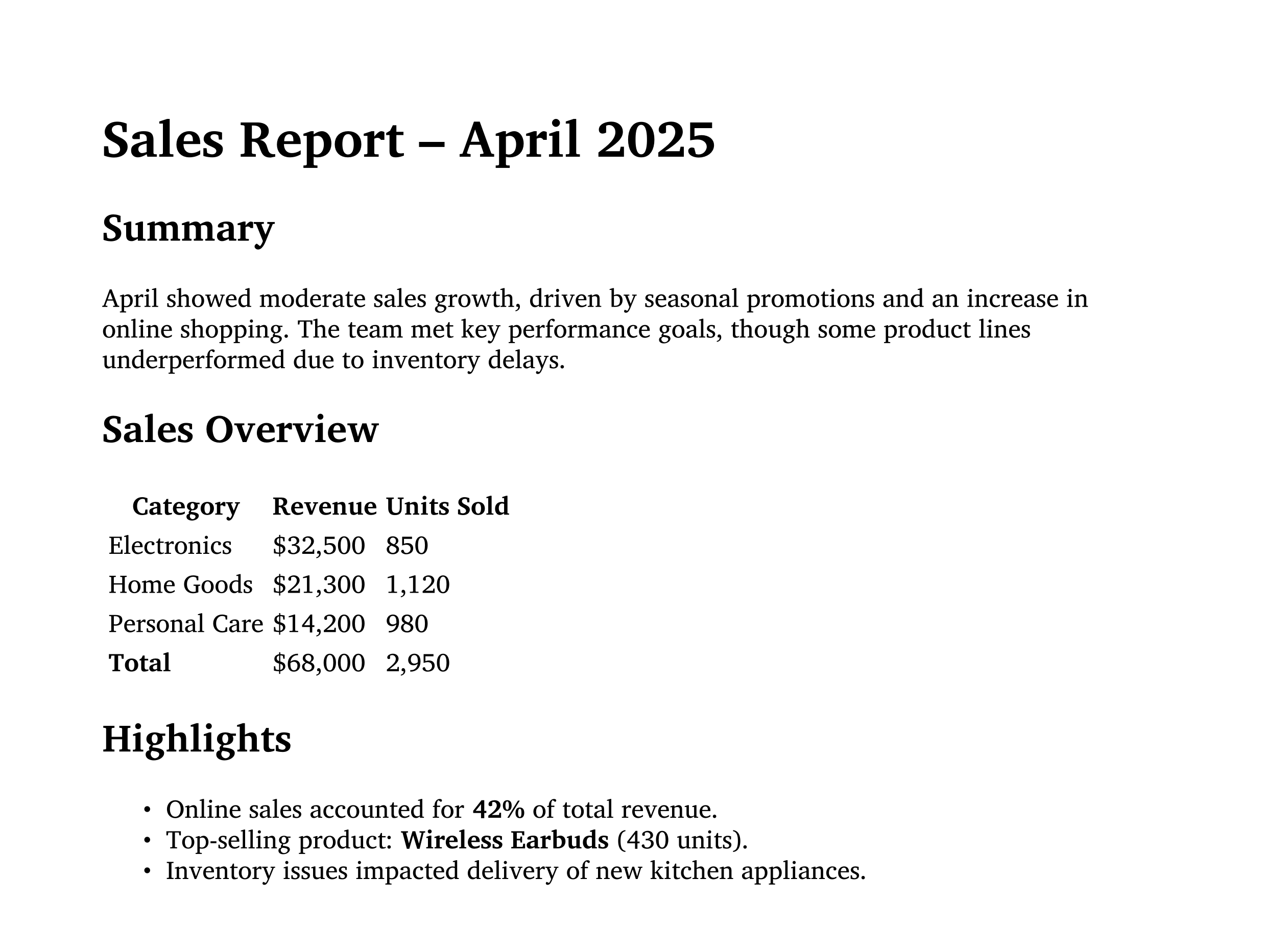
Here is a simple markdown file:
# Sales Report – April 2025
## Summary
April showed moderate sales growth, driven by seasonal promotions
and an increase in online shopping. The team met key performance
goals, though some product lines underperformed due to inventory
delays.
## Sales Overview
| Category | Revenue | Units Sold |
|---------------|----------|-------------|
| Electronics | $32,500 | 850 |
| Home Goods | $21,300 | 1,120 |
| Personal Care | $14,200 | 980 |
| **Total** | $68,000 | 2,950 |
## Highlights
* Online sales accounted for **42%** of total revenue.
* Top-selling product: **Wireless Earbuds** (430 units).
* Inventory issues impacted delivery of new kitchen appliances.
This is the code required to convert this into a PDF:
from markdown_pdf import MarkdownPdf, Section
with open("document.md") as f:
md = f.read()
pdf = MarkdownPdf()
pdf.add_section(Section(md))
pdf.save("document.pdf")
After importing the required items from markdown_pdf, the first thing we need to do is read the markdown text from a file. The markdown code is read into the string md as before.
Next, we:
- Create a
MarkdownPdfobject, which we will use to build our PDF document. - Add a section to the
pdfobject. The section contains the document content (the markdown text we read earlier). - Finally, we save the
pdfobject as a PDF file.
Here is a screenshot of the resulting PDF file:
Before we leave this, it is worth looking at the code for adding a section once again:
pdf.add_section(Section(md))
This code first creates a Section object, based on md, the contents of the markdown file. It then adds that section to the pdf object by calling add_section.
In this case, there is just one section, containing the entire document, which is typically what you might do when the document is quite small. However, we can add more than one section by repeating the add_section call, passing in different markdown to create the complete document.
There are a couple of reasons you might want to add a new section:
- It causes the new markdown to start a new page in the PDF.
- If you are styling the PDF (see below), it is possible to use a different style for different sections.
In addition, for a longer document such as a book, it might be convenient to place each chapter in a separate section just to make the files easier to work with.
Styling the PDF
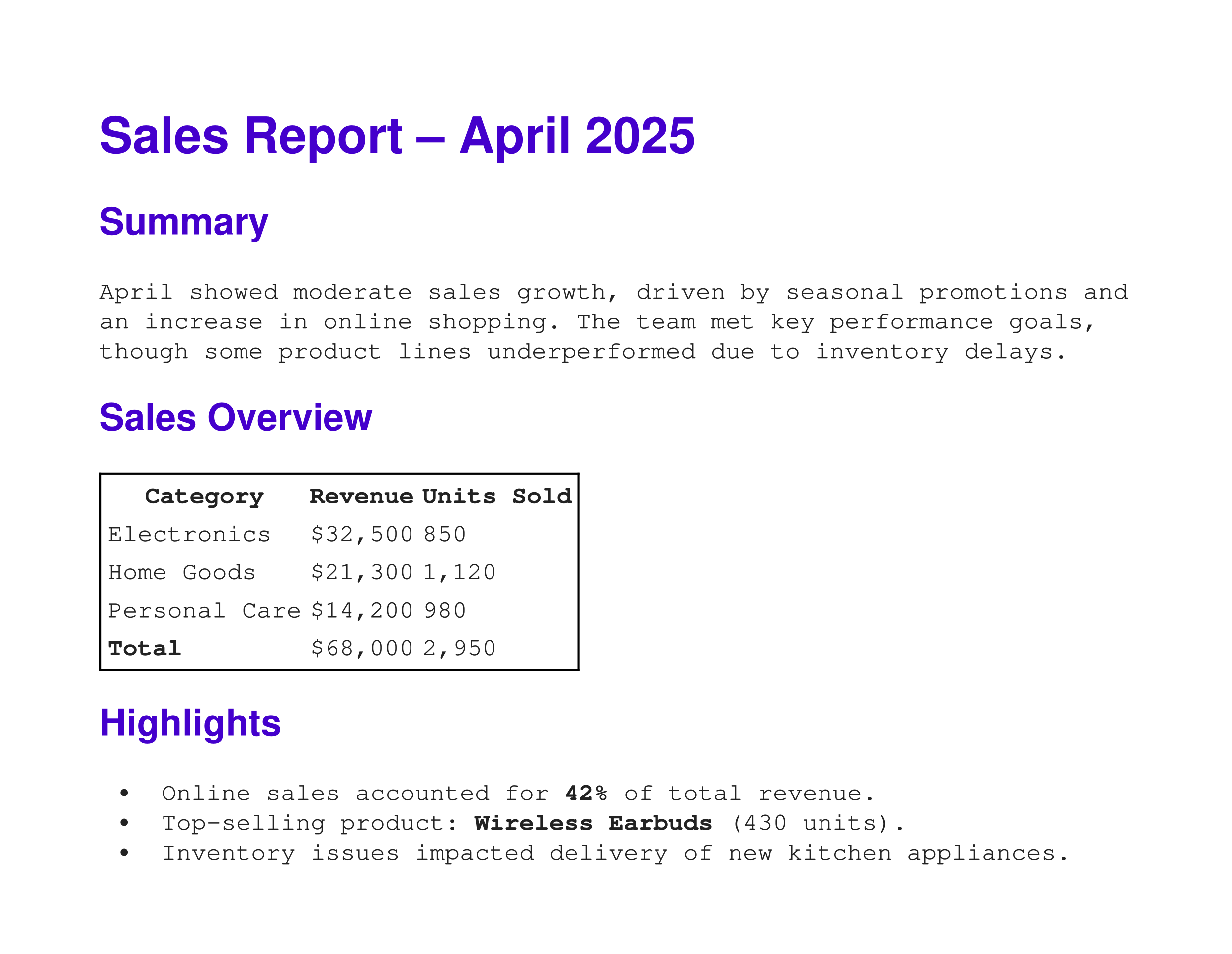
We can style the PDF using a simple CSS file. Here is the file we will use, called style.css:
body {
font-family: "Courier New", monospace;
color: #222;
}
h1, h2 {
font-family: 'Arial', sans-serif;
color: #40c;
}
table {
border: 1px solid black;
}
This style sets the body text font to a monospace font, with a dark grey colour. It sets the heading text to a sans-serif font with a deep purple colour. It also adds a black line around the outside of the table.
Using this CSS only requires one small change to our Python code. We need to read the CSS file into a string (like we did for the markdown file), then pass the string into the add_section call as the user_css parameter. Here is the new code:
from markdown_pdf import MarkdownPdf, Section
with open("document.md") as f:
md = f.read()
with open("style.css") as f:
css = f.read()
pdf = MarkdownPdf()
pdf.add_section(Section(md), user_css=css)
pdf.save("styled-document.pdf")
Here is the PDF it creates:
Other capabilities
markdown_pdf is quite a simple module, without too many options, but to finish off, we will look at some useful extra things it can do.
Section objects have several optional parameters (plus a toc parameter that we will cover later):
rootis a string representing the path to any extra files referenced in the markdown text, for example, any image files. It is usually a relative path. It defaults to ".", so if all the image files are in your working directory, it should be fine.paper_sizespecifies the paper size as a string. It supports "A0" through to "A10", "Letter", "Legal", and various other formats. Adding the suffix "-L" indicates landscape orientation (so "A4-L" is A4 landscape). You can also use "-P" for portrait, but that is optional, as portrait is the default orientation.bordersdefines a border area around the edges of the page that will not be marked. The page content will be laid out so that it is within those borders. The border is a list[left, top, right, bottom]. The default is[36, 36, -36, -36]. It is measured in points (1/72 of an inch), so the default is a half-inch border around the page. Notice that the right and bottom borders are negative.
The module will automatically create a table of contents (TOC) for the PDF file. But be aware that the TOC isn't part of the printed content of the PDF file. It is part of the metadata, and it usually appears as a sidebar when you open the PDF file in a PDF reader application (the exact way it works depends on which reader application you are using).
By default, the TOC includes every heading from level 1 right down to level 6. However, the toc_level parameter of MarkdownPdf controls this. For example, setting it to 2 means that only heading levels 1 and 2 are included in the TOC. Setting it to 0 disables the TOC altogether.
Section also has a toc parameter. Setting this false means that the headings in that section will not be added to the TOC, regardless of the toc_level. Here is a partial example of the TOC parameters:
pdf = MarkdownPdf(toc_level=3) # Only include heading levels 1 to 3 in TOC
pdf.add_section(Section(md1))
pdf.add_section(Section(md2))
pdf.add_section(Section(md3), toc=False) # Don't include headings in TOC
pdf.save("document.pdf")
We can add metadata to the PDF, like this:
pdf = MarkdownPdf()
pdf.meta["title"] = "Example PDF"
pdf.meta["author"] = "GraphicMaths"
pdf.add_section(Section(md))
pdf.save("document.pdf")
Again, this data will not appear in the printed content of the PDF, it will just be in the metadata. Supported fields are creationDate, modDate, creator, producer, title, author, subject, and keywords. The creationDate and modDate are automatically filled with the current date.
Join the GraphicMaths Newsletter
Sign up using this form to receive an email when new content is added to the graphpicmaths or pythoninformer websites:
Popular tags
adder adjacency matrix alu and gate angle answers area argand diagram binary maths cardioid cartesian equation chain rule chord circle cofactor combinations complex modulus complex numbers complex polygon complex power complex root cosh cosine cosine rule countable cpu cube decagon demorgans law derivative determinant diagonal directrix dodecagon e eigenvalue eigenvector ellipse equilateral triangle erf function euclid euler eulers formula eulers identity exercises exponent exponential exterior angle first principles flip-flop focus gabriels horn galileo gamma function gaussian distribution gradient graph hendecagon heptagon heron hexagon hilbert horizontal hyperbola hyperbolic function hyperbolic functions infinity integration integration by parts integration by substitution interior angle inverse function inverse hyperbolic function inverse matrix irrational irrational number irregular polygon isomorphic graph isosceles trapezium isosceles triangle kite koch curve l system lhopitals rule limit line integral locus logarithm maclaurin series major axis matrix matrix algebra mean minor axis n choose r nand gate net newton raphson method nonagon nor gate normal normal distribution not gate octagon or gate parabola parallelogram parametric equation pentagon perimeter permutation matrix permutations pi pi function polar coordinates polynomial power probability probability distribution product rule proof pythagoras proof quadrilateral questions quotient rule radians radius rectangle regular polygon rhombus root sech segment set set-reset flip-flop simpsons rule sine sine rule sinh slope sloping lines solving equations solving triangles square square root squeeze theorem standard curves standard deviation star polygon statistics straight line graphs surface of revolution symmetry tangent tanh transformation transformations translation trapezium triangle turtle graphics uncountable variance vertical volume volume of revolution xnor gate xor gate
